
[ad_1]
Earlier this week, the Internet had a conniption. YouTube has stammered around the world. Shopify stores are closed. Snapchat blinked. And millions of people could not access their Gmail accounts. The disruptions all come from Google Cloud, which has suffered a prolonged failure, also preventing Google engineers from proposing a solution. Thus, during a whole afternoon and at night, the Internet was blocked in a disabling ouroboros: Google could not repair its cloud, because it was broken.
As Google explained this week, the root cause of the outage was rather innocuous. (And no, they're not pirates.) At 2:45 pm ET on Sunday, the company launched what should have been a routine configuration change, a maintenance event for a few servers in a particular geographic area. When this happens, Google routinely redirects the tasks that these servers run on other machines, such as clients that change lines on the target when closing a registry. Or sometimes, it is important to suspend these jobs until the end of maintenance.
What happened next becomes technically complicated – a cascading combination of two incorrect configurations and a software bug – but had a simple result. Rather than temporarily letting go of this small group of servers, Google's automation software has canceled network control tasks across multiple sites. Imagine the traffic in Google's cloud as a car that approaches the Lincoln Tunnel. At that moment, its capacity actually passed from six to two tunnels. The result: a traffic jam on the Internet.
![]()
Nevertheless, even in this case, everything remained stable for a few minutes. Google's network is designed to "fail static", which means that even after a control plan has been disrupted, it can work normally for a short time. It was not long enough. At 2:47 pm ET, this occurred:
In such moments, all traffic does not fail in the same way. Google has automated systems to ensure that when it starts to sink, lifeboats fill up in a specific order. "The network has become congested and our network systems have correctly sorted the traffic overload and dropped more and less latency-sensitive traffic in order to preserve more latency-sensitive traffic flows," the report said. Google's vice president of engineering, Benjamin Treynor Sloss, "As much as urgent parcels can be sent by bike through the worst traffic jams". You see? Lincoln Tunnel.
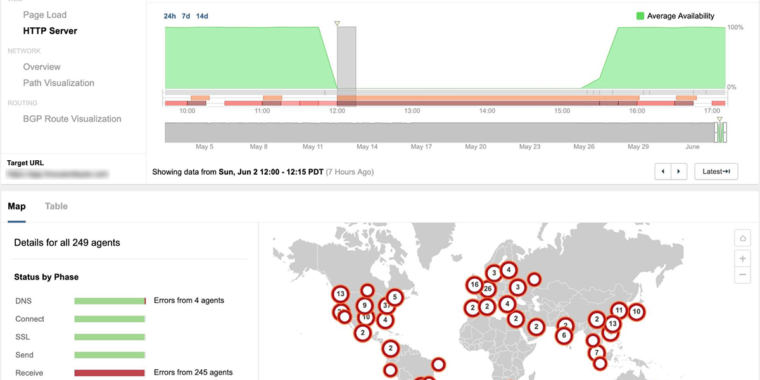
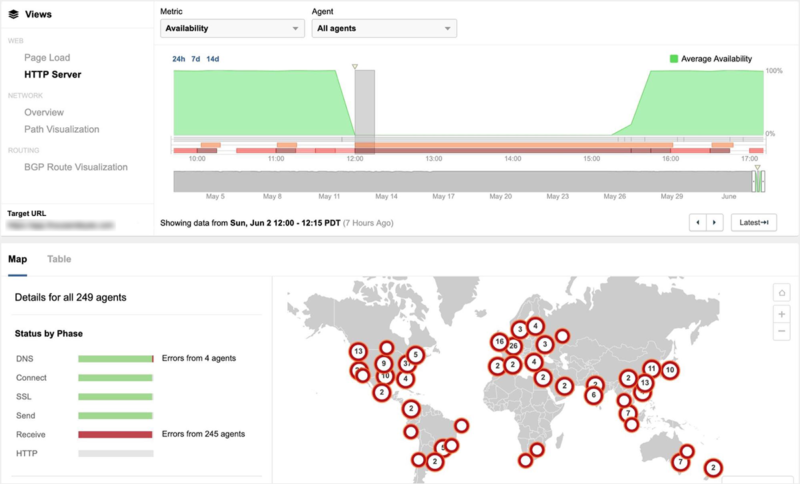
You can see what is Google's priority in the shutdown time of various services. According to Sloss, Google Cloud has lost nearly a third of its traffic, which is why third parties such as Shopify have been blocked. YouTube lost 2.5% of views in one hour. One percent of Gmail users have encountered problems. And Google search jumped briskly, at worst a barely noticeable slowdown in results.
"If I type in a search and it does not respond immediately, I go to Yahoo or something like that," says Alex Henthorn-Iwane, vice president of ThousandEyes' digital experiment monitoring company. . "So, it was a priority. It's sensitive to latency, and it's the cash cow. This is not a surprising business decision to make on your network. "
But these decisions do not just apply to the sites and services you saw flirting last week. In these moments, Google must sort not only user traffic, but also the network control plan (which tells the network where the traffic needs to be routed) and the management traffic (which includes the type of traffic). administrative tools that Google engineers would need to fix, for example, a configuration problem that hits a pile of offline internet).
"Management traffic because it can be quite bulky, you always pay attention. Giving priority to this is a bit scary, as it can eat away at the network if something goes wrong with your management tools, "says Henthorn-Iwane. "It's a bit of a Catch-22 that happens with network management."
Which is exactly what was played on Sunday. Google says its engineers were aware of the problem in less than two minutes. And even! "The debugging of the problem has been significantly hampered by the failure of competing tools on the now-saturated network usage," the company wrote in a detailed post-mortem report. "In addition, the magnitude of the outage and the consequential damage caused to the tool by network congestion made it difficult in the early precise identification of the impact and the accurate communication with customers. "
This "fog of war," as Henthorn-Iwane calls it, meant that Google had made no diagnosis until 6:01 pm ET, well over three hours after the onset of the troubles. An hour later, at 7:03 pm Eastern Time, he deployed a new configuration to stabilize the ship. At 8:19 pm, the network began to recover; At 9:10 pm Eastern time, the situation was back to normal.
Google has taken steps to ensure that a similar network failure does not happen again. It took the automation software that disrupts the work during offline maintenance, and the company said it would not bring it back until "the appropriate safeguards would be in place" to avoid a global incident. He also extended the time required for his systems to remain in "Fail Static" mode, leaving Google engineers more time to solve problems before customers feel the impact.
However, it is unclear whether Google, or any other cloud provider, can completely avoid such collapses. Networks do not have infinite capacity. They all make choices about what continues to work and what does not work in times of stress. And what's remarkable about Google's failure in the cloud is not the company's priority, but the fact that it's so open and precise about what's wrong. Compare that to the downtime of Facebook on a March day, which the company attributed to a "server configuration change that triggered a series of cascading problems," period.
As always, take the last hour of unavailability in the cloud to remind yourself that much of your Internet experience resides in servers owned by a handful of companies, and that these The latter are managed by humans and the latter make mistakes, some of which can undulate much further than seems anything close to reasonable.
This story originally appeared on wired.com.
[ad_2]
Source link