
[ad_1]
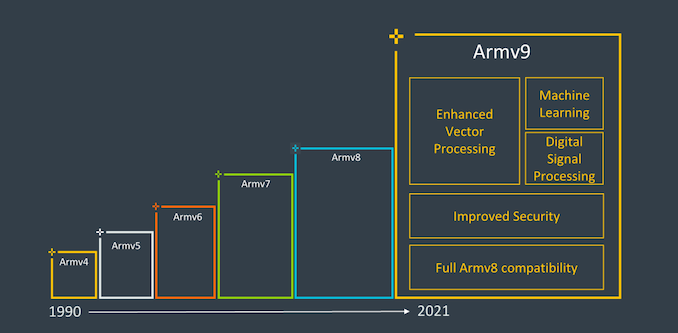
It was almost 10 years since Arm first announced the Armv8 architecture in October 2011, and it has been a pretty hectic decade of computing as the instruction set architecture saw increased adoption of the l ‘mobile space to server space, and is now starting to become mainstream in the market for consumer devices such as laptops and desktop machines to come. Over the years, Arm has evolved the ISA with various updates and extensions to the architecture, some important, others can be easily accessed.
Today, as part of Arm’s Vision Day, the company announces the first details of the company’s new Armv9 architecture, laying the groundwork for what Arm hopes to be the computing platform for the $ 300 billion. chips to come over the next decade.
The big question readers will probably ask themselves is what exactly differentiates Armv9 from Armv8 to justify such a big leap in ISA nomenclature. Honestly, from a purely ISA perspective, v9 is probably not as fundamental a leap as v8 was from v7, which introduced a completely different execution mode and instruction set. with AArch64, which had more microarchitectural ramifications than AArch32, such as extended registers, 64 -bit virtual address spaces, and many other improvements.
Armv9 continues to use AArch64 as its base instruction set, but adds some very important extensions to its capabilities that justify an increment in architecture numbering, and probably allow Arm to do some sort of re-baselining of the architecture as well. software not only the new v9 features but also the various v8 extensions that we have seen coming out over the years.
The three main new pillars of Armv9 that Arm sees as the primary goals of the new architecture are security, AI, and improved vector and DSP capabilities. Security is a really big topic for v9 and we’ll go into the new details of the new expansions and features in a bit more detail, but eliminating the DSP and AI features first should be simple.

The biggest new feature promised with the new Armv9 compatible processors that will be immediately visible to developers and users is probably the basis of SVE2 as the successor to NEON.
Scalable Vector Extensions, or SVE, in its first implementation, was announced in 2016 and first implemented in Fujitsu’s A64FX processor cores, now powering the world’s No.1 supercomputer Fukagu in Japan. The problem with SVE was that this first iteration of the new variable vector length SIMD instruction set was rather limited in scope and targeted more at HPC workloads, lacking many more versatile instructions that were still covered by NEON.
SVE2 was announced in April 2019 and sought to address this issue by supplementing the new scalable SIMD instruction set with the instructions needed to serve more varied DSP-like workloads that still use NEON.
The advantage of SVE and SVE2 beyond adding various modern SIMD capabilities is their variable vector size, ranging from 128b to 2048b, allowing variable granularity of 128b of vectors, regardless of what the actual hardware is on. works. From a vector processing and programming perspective alone, this means that a software developer would only have to compile their code once, and if in the future a processor came out with, for example, pipelines running native 512b SIMD, the code would be able to already take advantage of the full width of the units. Likewise, the same code could run on more conservative designs with lower hardware execution capability, which is important to Arm as they design processors from IoT, to mobile, to data centers. It also does all of this while staying within the 32b encoding space of the Arm architecture, while alternative implementations such as on x86 must add new extensions and instructions depending on the size of the vector.
Machine learning is also considered an important part of Armv9, as Arm sees more and more ML workloads become commonplace in the years to come. Running ML workloads on dedicated accelerators will naturally remain a requirement for anything critical in terms of performance or energy efficiency, but there will always be massive new adoption of smaller reach ML workloads. which will run on processors.
Matrix multiplication instructions are essential here and will represent an important step towards seeing wider adoption across the ecosystem as a core feature of v9 processors.
In general, I see SVE2 as probably the most important factor that would justify switching to a v9 BOM as this is a more definitive ISA feature that sets it apart from v8 processors in everyday use, and that would justify l software ecosystem is disappearing. deviate from the existing v8 stack. This has actually become a problem for Arm in the server space as the software ecosystem is still basing software packages on v8.0, which unfortunately lacks the very important v8.1 system extensions.
Having the entire software ecosystem moving forward and being able to assume that the new v9 hardware has the capability of the new architectural extensions would help move things forward and possibly fix part of the current situation.
However, v9 is not only about SVE2 and the new instructions, it also focuses on security, where we will see more drastic changes.
[ad_2]
Source link