
[ad_1]
Last week, we released our review on iPhone XS and XS Max, in which we have deepened the various aspects of the phones, especially the section on the processor performance of the A12. However, I wanted to deepen a little more processor performance than what I had time during the initial review, which I can finally get around now. The small kernels of the A12 were particularly useful in this article because the small kernels of Apple have not been thoroughly investigated to date. As it is still an important topic, I publish this part here as a pipeline and integrate it as an additional page in the journal:
The μarch A12 Tempest: a fierce little heart
Apple first introduced a "small" processor core alongside Twister hearts of the SoC A10, fueling the iPhone 7 generation. We never really had the opportunity to dissect these cores, and over time years ago, there was a little mystery around them as to what they are capable of.
Apple's introduction of a heterogeneous CPU topology has been one of the biggest validations for Arm designs. Having a low-power discrete processor on a SoC is a simple matter of physics: it's simply not possible to have larger microarchitectures, to reduce power as efficiently as if you were using a smaller, separate block. Even in a perfectly synchronized mythical microarchitecture, you would not be able to combat the static leaks present in larger processor cores, which would have the negative consequence of being part of the daily energy consumption. a device, even for small workloads. Powering the large cores of the processor and replacing it with a much smaller processor can reduce static leaks and (if designed as such) improve the energy efficiency of dynamic leaks.
The Tempest cores of the A12 are now the third iteration of this "small" microarchitecture and, since the A11, they are now completely heterogeneous and operate independently of the big hearts. But the question is this: is it the third iteration or has Apple done something more interesting?
The Tempest microcomputer is an off-side microarchitecture with a width of 3: already out of reach, which means it has very little to do with the "small" Arms, such as the A53 and A55, because they are simpler in order. drawings.
The Tempest core runtime pipelines are also relatively small: there are only two main pipelines capable of performing simple ALU operations; during this time, one of them also makes integer and PF multiplications, and the other is able to make PF additions. We basically have two main execution ports for each of the most complex pipelines behind them. In addition to the two main pipelines, there is also a dedicated combined load / storage port.
What is very interesting here is that it essentially looks like Apple's Swift microarchitecture from Apple's SoC A6. It is not very hard to imagine that Apple would have recycled this design, transferred it to 64-bit, and now uses it as a lean disused machine serving as a lower processor core. If this is actually derived from Swift, then above the three execution ports described above, we should also find a port dedicated to the integer and fp divisions, so as not to block the main pipelines when such an instruction is powered.
Tempest cores have a maximum frequency of 1587 MHz and are served by 32 KB instruction and data caches, as well as a 2 MB higher shared cache that uses power management for partially disable SRAM banks.
As far as energy efficiency is concerned, Tempest cores were basically my main candidate to try to get some sort of comparison from one apple to the other between A11 and the A & R. # 39; A12 for energy efficiency. I did not see any major differences in the hearts apart from the bigger L2, and Apple also kept the frequencies similar. Unfortunately, "similar" is not identical in this case; Since the small cores of the A11 can grow up to 1694 MHz when there is only one active thread, I really did not have a way to measure iso-frequency performance as well.
I used SPEC at a frequency of 1587 MHz simply by running a second dummy wire on another core while the main workloads were benchmarking. And I tried to get power figures with this method by regression testing the impact of the dummy wire. However, the power was almost identical to that measured at 1694 MHz. That's why I dropped this idea and we just have to keep in mind that the A11's Mistal cores were running 6.7% faster than the following tests:
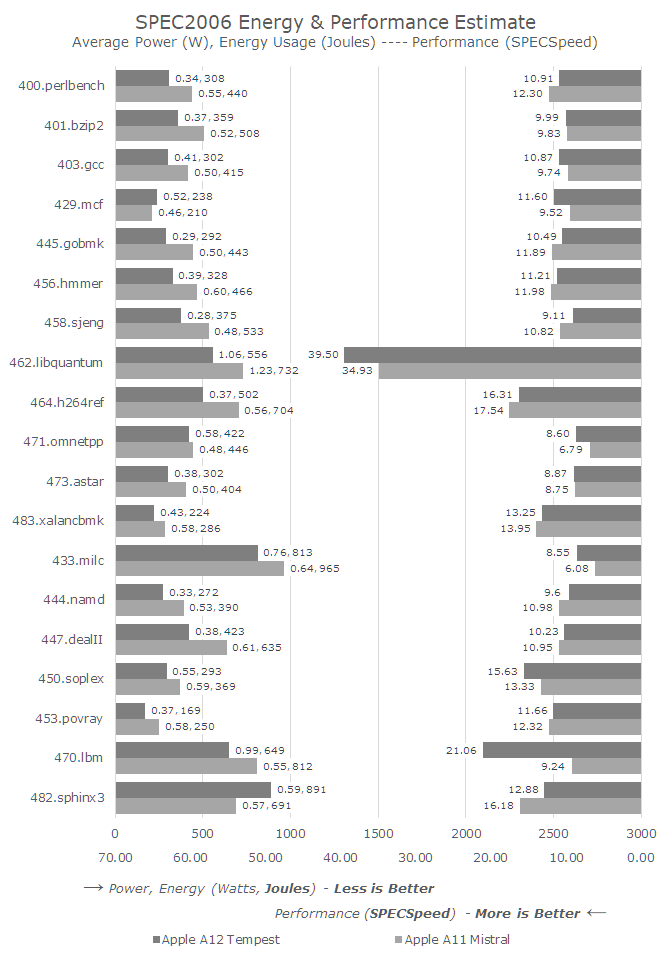
As with large Vortex kernels, the most important improvements for new Tempest kernels are in memory-aware performance tests. The benchmarks in which Tempest loses against Mistral are primarily performance-related, and because of the frequency-related disadvantage, it is not surprising that the A12 loses in this particular, single-threaded scenario.
Overall, in addition to memory enhancements, the performance of new Tempest cores is very similar to that of last year's Mistral cores. It's great because we can also study energy efficiency and perhaps learn something more concrete about the benefits of the 7 nm TSMC manufacturing process.
Unfortunately, improvements in energy efficiency are not always conclusive and all the more disappointing. In all SPECint2006 workloads, the Tempest-driven A12 was 35% more energy efficient than the A11 driven by Mistral. Since Mistral nuclei were operating at a higher frequency in this test, the actual efficiency gains for A12 would likely be even lower at an ISO frequency level. Of course, we're still looking at a general comparison of ISO performance here, because the improvements in memory in the A12 release made it possible to push Tempest cores to an almost identical whole-suite score for higher-rate Mistral cores.
In all the criteria of PF, Tempest was only 17% more efficient, even if its performances were better than those of Mistral nuclei of the A11.
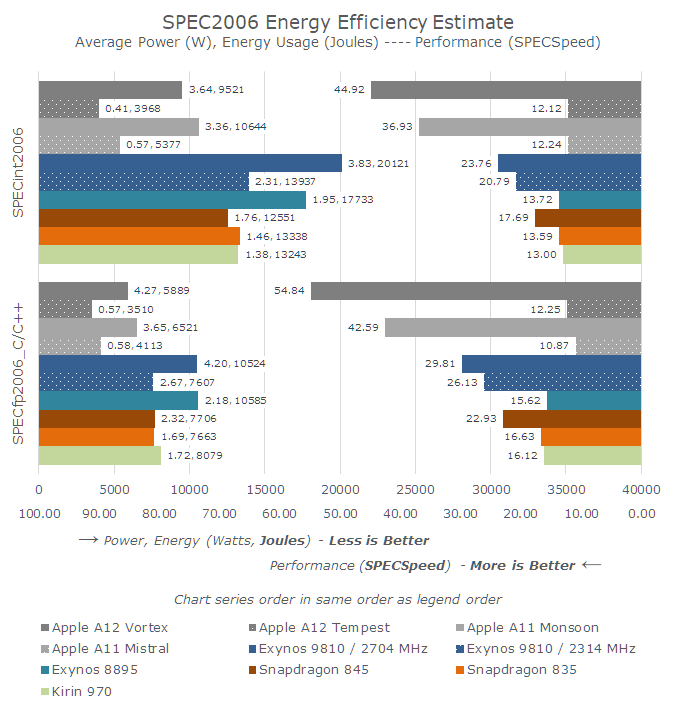
Comparing the small hearts A11 and A12 with their big brothers and the competition of Arm, the results are not very surprising. Compared to big hearts Apple, small hearts offer only one-third to a quarter of performance, but they also consume less than half of the energy.
What surprised me a lot was to see how Apple's small hearts compare to the Cintech-A73 of Armiste under SPECint. Here, Apple's small kernels almost match the performance of Arm's high performance cores 2 years ago. In the entire SPEC workloads, A12 Tempest is almost equivalent to a 2.1 GHz A73.
However, in SPECfp workloads, small kernels are not competitive. The lack of dedicated floating-point execution resources puts hearts at a disadvantage, even though they still offer great energy efficiency.
The small kernels of Apple are generally much more powerful than one might think. I have collected incomplete SPEC figures on the Army A55 (it takes time!) And in general, the difference in performance here is 2-3x, depending on the benchmark. In recent years, I felt that Arm's low performance range had become inadequate in many workloads. This may also be why we are going to see a lot more SoC at three levels (like the Kirin 980) in the near future. . In the current state of affairs, the gap between the maximum performance of small cores and the most effective point of poor performance of the largest continues to grow in one direction. So I'm wondering if it's still worth keeping a microarchitecture in order for Arm's efficiency hearts.
Neural network inference performance on the A12
Another important and mysterious aspect of the new A12 was SoC's new neural engine, announced by Apple as designed internally. As you may have noticed in the matrix shot, it is a rather large block of silicon, much like the size of the two large Vortex processor cores.
To my surprise, I discovered that Master Lu's AImark benchmark was also compatible with iOS and that it was using Apple's CoreML framework even better to accelerate the same inference models as on Android. I focused on the latest generations of iPhone, as well as on a few key Android devices.
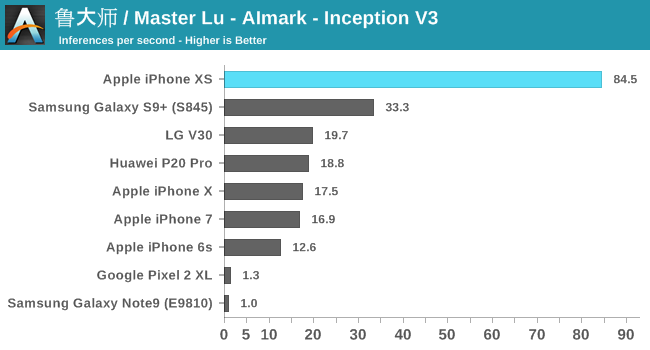
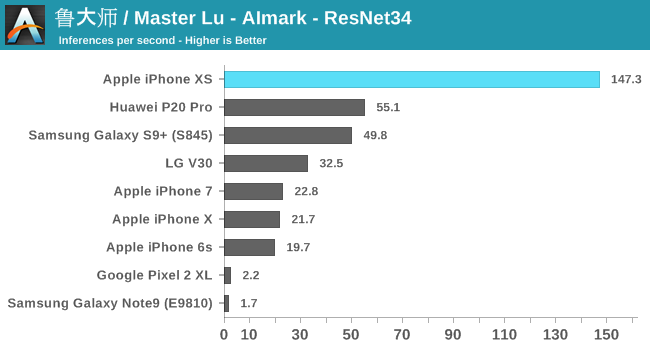
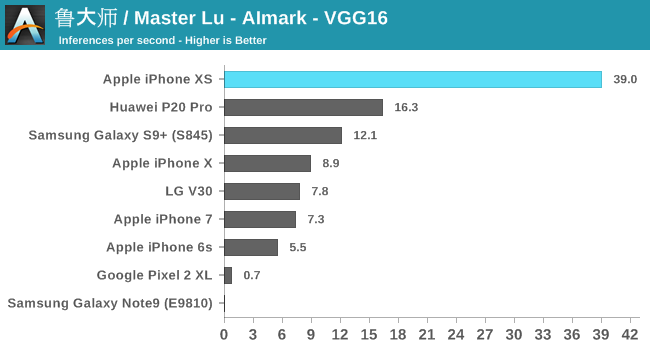
Overall, Apple's 8x performance reports have not been fully confirmed in this test suite, but we're seeing strong improvements from 4 to 6.5x. There is a disadvantage here with the old iPhone: as you can see in the results, the iPhone X based on A11 has performance quite similar to the phones of the previous generation. What happens here is that Apple runs CoreML on the GPU. It seems to me that the NPU of the A11 might never have been publicly exposed via APIs.
The Huawei P20 Pro's Kirin 970 is about 2.5 times behind the new A12 – which coincides with the 2 announced TOPs compared to the 5 TOPs announced for the capacities of the two respective NPUs of the SoC. The new Kirin 980 should be able to significantly reduce this gap.
Qualcomm's Snapdragon 845 also behaves very well, with the Kirin 970. AImark uses the SNPE framework to speed inference because it does not yet support NNAPI. Pixel 2 and Note9 gave terrific results in that both had to fall back on processor-accelerated libraries.
In terms of power, I'm not very comfortable with the power of publishing on the A12 because of the way the workload was visibly transactional: the deduction workload increased the consumption energy up to 5.5 W, with smaller gaps between the two. Without really knowing what is happening between peaks of activity, the average power values for the entire test can vary considerably. Nevertheless, the fact that Apple wants to climb to 5.5 W means that they strongly push the limits of consumption and strive to get the best performance in a burst. The power of the GPU-accelerated iPhone peaked between 2.3W and 5W, depending on the inference model.
Source link
