
[ad_1]
Les accélérateurs d’apprentissage automatique Radeon Instinct MI50 et MI60 complètent la première attaque d’AMD sur le marché des centres de données. Dans Radeon Instinct MI50 et MI60, les GPU reposent sur l’architecture Vega, qui a non seulement porté et réduit l’AMD à 7 nanomètres, mais l’a considérablement redessinée. AMD veut ainsi concurrencer Nvidias Tesla et conquérir une part de marché sur le marché des accélérateurs de centres de données estimé à 12 milliards de dollars.
Selon AMD, le Radeon Instinct MI60 est actuellement l’accélérateur HPC le plus rapide avec interface PCI Express en termes de performances de calcul en virgule flottante avec numéros FP32 et FP64. La limitation au PCIe est nécessaire car le Tesla V100 de Nvidia avec le port SXM2 et NVLink 2.0 est toujours un peu plus rapide, contrairement à la version PCIe du Tesla V100.
Enfin, grâce à la mémoire HBM2, les Radeon Instinct MI50 et MI60 sont les premiers accélérateurs avec un taux de transfert de mémoire de 1 To / s. AMD prévoit de lancer les MI50 et MI60 au quatrième trimestre de 2018.

Radeon Instinc MI60 Schéma fonctionnel: similitudes avec Vega 10.
(Image: Heise / Carsten Spille)
Merci à 7nm production à de nouveaux sommets
Le processus TSMC 7 nm utilisé pour fabriquer le processeur graphique (GPU) permet de doubler la densité du transistor tout en offrant une fréquence d'horloge supérieure de 25% ou une consommation d'énergie inférieure de 50%. Dans le cas des nouveaux GPU Vega, AMD n'a pas encore dépbadé l'horizon de 20%, ce qui donne une fréquence estimée à 1,8 GHz. La consommation électrique nominale est de 300 watts.
Les références du nouveau GPU sont similaires à celles du GPU 2017 Vega 10 à première vue. Les deux ont quatre unités de trame, 4096 unités de shader regroupées dans 64 unités de calcul et (vraisemblablement) 64 amplificateurs de trame. La variante MI50 possède seulement 16 Go de mémoire HBM2 au lieu de 32 Go, 60 CU (3840 shaders) et fonctionne avec 1,75 GHz calculé. La nouvelle Vega comprend plus de 13,2 milliards de transistors sur une surface de puce de 331 mm².

Spécifications techniques Radeon MI50 et MI60
(Image: Heise / Carsten Spille)
Les nouveaux GPU Vega ont reçu d'importants ajouts au calcul haute performance (HPC). Cela inclut le doublement des lignes de transfert de l'interface mémoire, qui gère désormais quatre puces HBM2 avec un total de 32 Go sur 4096 lignes de données.
Les unités arithmétiques ont beaucoup investi dans la performance en virgule flottante double précision (FP64), qui peut désormais être réalisée à la moitié de la vitesse du FP32 – la génération précédente était encore un maigre 1/16. Les caches L1 et L2 ainsi que les registres GPU sont désormais également protégés contre les erreurs via ECC.
L'horloge de la mémoire HBM2 a été augmentée à 1 GHz, de sorte qu'elle transmet maintenant un téraoctet complet par seconde. L'interface système est également deux fois plus rapide qu'auparavant grâce à PCIe 4.0 x16 avec une capacité totale de 64 Go / s (32 Go / s par direction). Le prochain Epyc "Rome" en 7 nm sera probablement le premier processeur x86 doté de PCIe 4.0.
Mais les liens à l'infini sont encore plus importants pour l'évolutivité du centre de données. Deux d'entre eux, chacun avec 100 Go / s apportent MI50 et MI60; C’est l’équivalent AMD du NVLink 2.0 de Nvidia, pour ainsi dire. Un bus en anneau à l'infini relie quatre accélérateurs Radeon Instinct, donnant à chaque GPU l'accès à toute la mémoire connectée (mémoire unifiée). Deux de ces groupes de quatre peuvent à leur tour communiquer entre eux via PCIe 4.0. Il y a aussi la virtualisation matérielle.
Radeon Instinct MI60: Débit arithmétique théorique.
(Image: Heise / Carsten Spille)
Perspectives de performance
Le débit arithmétique pur a augmenté d’un peu moins de 18% par rapport à la Radeon Instinct MI25, âgée de deux ans. Toutefois, AMD entend atteindre des valeurs 2,8 fois supérieures à celles de son prédécesseur, le MI25, dans le benchmark d’apprentissage automatique Resnet-50 avec une précision FP16, notamment grâce à la mémoire plus rapide.
Avec la précision FP32, les repères Resnet-50, Inception-4 et VGG16 ont augmenté de plus de 50%. L’augmentation des performances avec une précision FP32 dans le référentiel Alexnet serait toutefois supérieure à 25% et donc supérieure à l’augmentation théorique du débit.
Même contre le plus réputé des accélérateurs HPC, le Tesla V100 de Nvidia, AMD considère que le MI60 est deux fois moins compétitif. Dans Resnet-50, SGEMM et DGEMM, la différence de performance n’est que de -6 à +7%. Pour Resnet-50, cependant, AMD a choisi la version FP32, laissant les cœurs de tenseurs de Nvidia dehors.
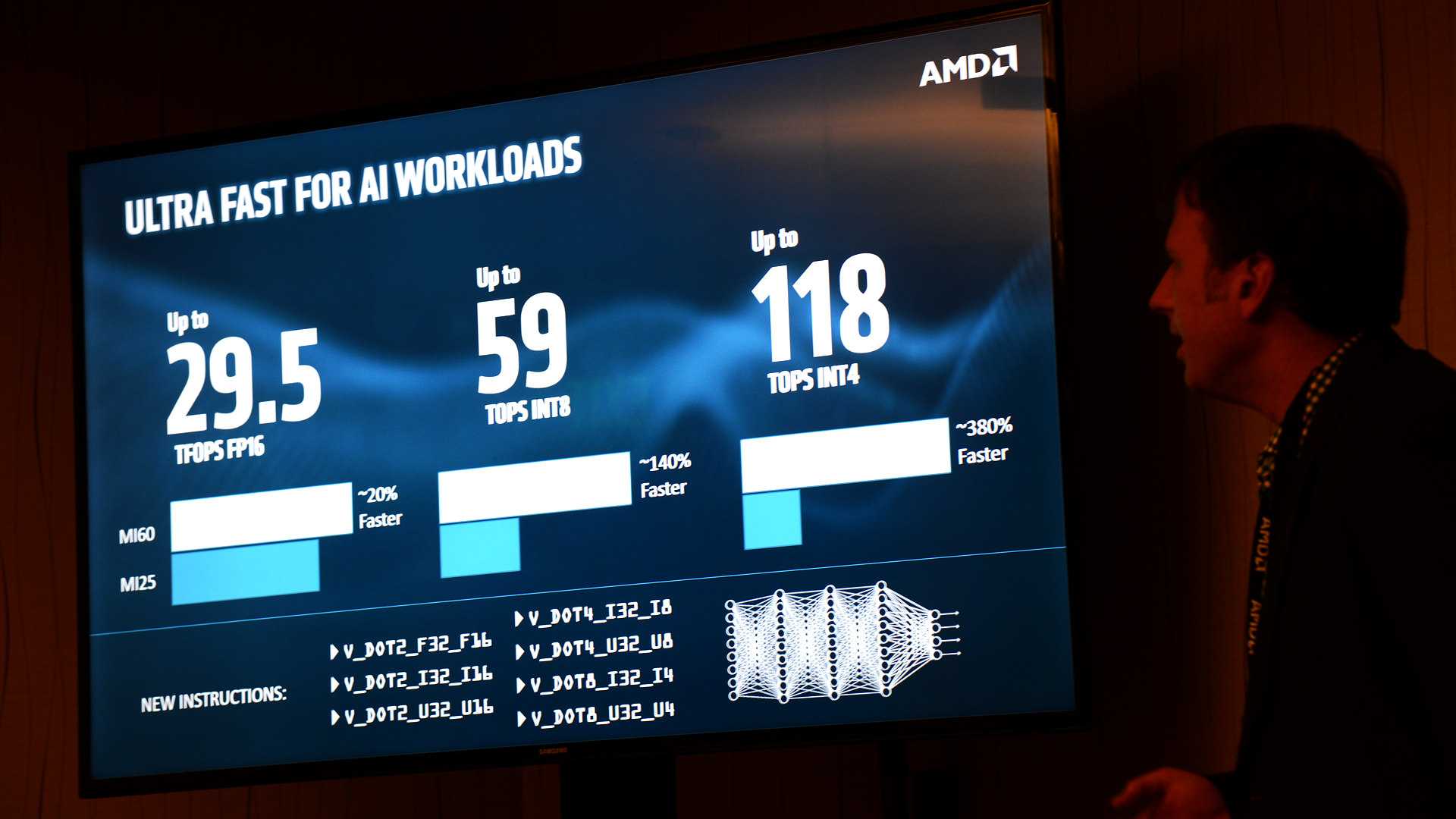
Pour augmenter les performances d'apprentissage machine, le processeur graphique AMD peut non seulement effectuer des calculs FP16 à une vitesse deux fois supérieure, mais également gérer des types de données plus petits, tels que INT8 ou INT4, avec un débit doublé ou quadruplé. Il en va de même pour 118 Tera OPS pour le MI60 au compteur.
(CSP)
À la page d'accueil
Source link
